février 2023
Peut-on déterminer la paternité de l’implémentation (et l’évolution) d’une fonctionnalité variable à partir du code en appliquant les méthodes de détermination de paternité aux endroits où la variabilité est implémentée ?
Nous nous concentrerons sur les variables d’environnement.
Lien du repository git : https://github.com/Yann-Brault/si5-rimel-22-23-e-2
Nous sommes quatre étudiants ingénieurs en dernière année à Polytech Nice Sophia, spécialisés en Architecture Logiciel :
Dans de nombreux projets de grande envergure, nous retrouvons de la variabilité. Afin d’illustrer au mieux ce qu’est la variabilité, nous allons prendre un exemple concret. JetBrains est l’entreprise qui a créé la suite d’IDE Intellij, WebStorm, Clion… Ils ont une suite logicielle très vaste, et très développée. Si vous avez déjà utilisé plus de 2 de ces IDE, vous aurez sûrement remarqué que l’affichage, la forme du logiciel, les paramètres, se ressemblent énormément, voire sont les mêmes dans la majorité des cas.
Ces différents IDE utilisent de la variabilité pour fonctionner. C’est-à-dire, quand JetBrains veut créer un nouvel IDE, l’équipe de développement ne repart pas de 0. Elle va réutiliser une base déjà existante. De cette manière les équipes peuvent être sûres qu’elles modifient un code déjà fonctionnel et testé à très grande échelle, et n’ont plus qu’à modifier le comportent et ajuster les fonctionnalités en fonction du langage ciblé par ce nouvel IDE.
Donc quand JetBrains va créer un nouvel IDE, qui s’appelle par exemple JetRimel, les équipes vont prendre la base de Intellij, et adapter le comportement et va y insérer de la variabilité. Voici un exemple :
.env
MY_CURRENT_IDE="JetRimel"
myClass.js
if (process.env.MY_CURRENT_IDE === "JetRimel") {
// Show the header in black
}
if (process.env.MY_CURRENT_IDE === "IntelliJ") {
// Show the header in white and add the Git Extenssion
}
if (process.env.MY_CURRENT_IDE === "DataSpell") {
// When right click, allow only to create Jupyter Notebook files
}
Ceci est un exemple très simplifié, mais relativement parlant. JetBrains va, dans son fichier .env insérer des variables d’environnement, notamment une, nommé MY_CURRENT_IDE qui donne le type d’IDE sur lequel il fonctionne, et au moment du runtime, le logiciel va savoir quoi faire. En faisant ceci, une nouvelle valeur est injectée dans le code et elle a pour but de modifier le comportement de ce dernier.
Maintenant que nous savons ce qu’est la variabilité, revenons-en à la paternité.
La paternité dans le développement de logiciels est la caractérisation des contributions dans le code. Tout développeur qui crée, édite ou bien supprime du code sera considéré comme ayant un lien de paternité avec ce code.
Il est légitime de se poser la question quant à la pertinence de quantifier la paternité, car du point de vue de notre exemple précédent, les applications semblent limitées. Prenons un autre exemple plus parlant.
Imaginez-vous prendre position dans un projet déjà établi, et vous êtes confronté à de la variabilité. Etant nouveau, et donc sans connaissance de la base de code, vous n’avez aucune idée de pourquoi cette variabilité est présente et à quoi elle sert. Il serait alors très opportun d’avoir à disposition un outil permettant d’analyser la paternité de cet extrait de code en particulier (donc de remonter à travers les commits ), afin de, soit lire le message du commit dans le but de se faire une idée du pourquoi, voire même afin contacter le développeur qui a intégré quelque chose que vous ne comprenez pas même après lecture du commit et de la documentation s’il y en a une.
En plus d’avoir un aspect pratique, cet outil permettrait aussi de faire des statistiques intéressantes, afin de savoir qui est majoritairement à l’origine de la variabilité, qui créé le plus de variabilité, pour permettre, potentiellement, aux équipes du management d’avoir une métrique globale et une vue d’ensemble sur le projet en cours.
Cette introduction nous a semblé utile d’abord car nous n’étions, au sein du groupe, pas tous familié avec les notions de variabilité ni de paternité. Elle avait également pour but de nous aider à vulgariser le sujet, car, comme dirait M. Mortara (Docteur qui est intervenu dans le sujet du projet), “si vous n’êtes pas capable d’expliquer votre sujet avec des mots simples, alors vous avez du mal à comprendre vous-même votre sujet et vous avancerez mal”.
Maintenant que nous avons introduit notre sujet et notre problématique principale nous allons énoncer nos différentes hypothèses de travail. Nous présentons de plus quel découpage de la problématique, et à l’aide de quelles expériences, nous allons apporter nos réponses.
Voici notre sujet initial :
Peut-on déterminer la paternité de l’implémentation (et l’évolution) d’une fonctionnalité variable à partir du code en appliquant les méthodes de détermination de paternité aux endroits où la variabilité est implémentée ?
En analysant la question en détails, nous pouvons la résumée de la manière suivante :
En détectant où la variabilité est implémentée, comment déterminer la paternité de celle-ci ?
Ce petit résumé correspond à notre introduction, et aux potentiels cas d’utilisations associés. Notre but est donc de :
- Détecter la variabilité
- Analyser la paternité de cette variabilité
Il y a plusieurs façons de détecter de la variabilité. La variabilité se trouve dans les mécanismes de pré-processing avec les instructions#ifdef, ou dans les codes orientés objets à l’aide de différentes pratiques propres à ce paradigme telles que la surcharge ou encore l’héritage, mais aussi grâce à des variables d’environnements. C’est ce dernier point qui nous intéresse.
Nous pouvons donc compléter notre but :
- Détecter la variabilité grâce aux variables d’environnements
- Analyser la paternité de cette variabilité
Avec notre reformulation, le problème semble plus abordable. Afin de réaliser au mieux notre étude, il est nécessaire de décomposer ces grandes questions en sous-questions, pour avoir un plan.
Nous avons recensé toutes les étapes par lesquelles nous sommes passés.
Nous allons reformuler une nouvelle fois notre problème, mais cette fois-ci c’est la question à laquelle nous allons essayer de répondre.
Peut-on identifier, à gros grain, la paternité des variables d’environnement dans un code ?
Cette question implique 2 sous-questions :
- Qui a créé pour la première fois la variable d’environnement ?
- Qui a édité cette variable d’environnement dans le code ?
De ces deux questions, nous nous proposons ensuite de répondre à la question suivante :
_Comment mesurer la paternité d’une variabilité à l’instant T et au fil du temps ? _
Lors du découpage du projet, nous voulions aller encore plus loin qet pousser l’analyse jusqu’à la détection des impacts liés à l’utilisation / modifications des variables d’environnement, cependant, après discussion avec plusieurs encadrants, nous nous sommes rendus-compte qu’il valait ne pas s’aventurer sur ce terrain qui rendrait l’analyse trop complexe.
A première vue, il peut sembler simple de trouver des variables d’environnements dans un projet, cependant, ce n’est pas si simple que ça. En effet, tous les langages ont leur propre manière de fonctionner.
Nous détaillerons plus tard la démarche, mais il est clair que ce problème est la partie sensible de la détection des variables, qui nous a demandé beaucoup de temps et beaucoup de réflexion. De plus, c’est un point central de notre projet, si nous n’arrivons pas à détecter les variables d’environnements correctement, nous n’avons rien à analyser.
Une fois que nous aurons détecté les variables d’environnements dans le code, nous devrons déterminer la paternité de celles-ci. Pour cela, nous ferons une première passe relativement simpliste, c’est-à-dire d’associer à chaque développeur du projet, un pourcentage de paternité.
Admettons que nous avons un projet qui contient 3 implémentations de variabilité, par exemple :
myClass.js
1 if (process.env.MY_CURRENT_IDE === "JetRimel") {
2 // Show the header in black
3 }
4 if (process.env.MY_CURRENT_IDE === "IntelliJ") {
5 // Show the header in white and add the Git Extenssion
6 }
7 if (process.env.MY_CURRENT_IDE === "DataSpell") {
8 // When right click, allow only to create Jupyter Notebook files
9 }
Admettons que la ligne 1 ait été écrite par George, et que la ligne 4 et 7 par Moris. Dans ce cas-là, Moris aura un pourcentage de responsabilité de modifications de 66% tandis que George aura un score de 33%.
Malgré le fait que cette métrique soit assez abstraite, elle permet à des chefs de projet de savoir qui est responsable en majorité de la paternité, et de potentiellement prendre des dispositions par rapport à cela.
De ce fait, imaginez que vous êtes chef de projet chez JetBrains, et que vous vous rendez compte que sur tous les développeurs de votre équipe, il y en a un, qui est à 2 ans de la retraite et qui a 80% de responsabilité de paternité. C’est problématique, parce qu’une fois parti, il ne pourra plus vous aider. Donc là en tant que chef de projet, vous pouvez prendre les reines et lui faire faire des interviews pour préparer la suite, ou même essayer de splitter cette responsabilité sur des nouveaux développeurs.
Nous pouvons ensuite aller faire cette mesure pour chaque commit, et donc avoir une vue globale du pourcentage de responsabilité de paternité au fil du temps.
Nous souhaitons implémenter une solution qui permettrait à un utilisateur de pouvoir accéder facilement à l’historique de toutes les modifications concernant un bout de code en particulier.
Il s’agirait d’un Git Blame simplifié et bien moins pénible à parcourir.
Cette section aura pour ligne de conduite la détection de variables d’environnements dans un projet. C’est une partie relativement complexe car l’utilisation des variables d’environnement dans un code est très dépendant de son langage de programmation. Alors oui, cela peut-être un réel avantage si l’on souhaite trouver les variables d’environnements dans un projet, mais si l’on cherche à analyser une variété de projets dans des langages particuliers, cela est compliqué.
La première étape est de faire un état de l’art de ce qui existe déjà. Nous avons procédé à 2 méthodes, la première, effectuer des recherches via Google Scholar ensuite faire des recherches plus générales sur le web.
Nous avons trouvé un article intéressant nommé “A framework for creating custom rules for static analysis tools”[Dalci&Steven] Cet article est intéressant et décrit comment créer des règles personnalisées pour faire de l’analyse statique de code via l’outil Fortify Software Source Code Analyzer. Un outil comme celui-ci serait parfait pour nous, car on pourrait lui donner des règles, et il ira faire l’analyse statique du code. Cependant, ce logiciel est sous licence, nous ne pouvons donc pas l’utiliser, de plus, nous n’avons pas trouvé de version en open-source.
Un outil réalisant une analyse de code statique est SonarQube, nous pouvons également lui donner des règles personnalisées, cependant cet outil est spécialisé dans l’étude de la qualité du code notamment pour fournir des métriques telle que la couverture de test ou la qualité du code mais n’est pas appliqué à la détection de variables d’environnement. Nous avons donc fait le choix de créer notre propre outil, sous Python, qui irait explorer les fichiers et trouverait directement les variables d’environnements.
Avant de continuer, revenons à notre problème. Nous cherchons à trouver des variables d’environnements dans un code. Notre première idée fut d’utiliser des projets qui sont déployer avec Docker via un système de docker-compose. En effet, dans les docker-compose, nous trouvons les variables d’environnement qui seront injectées. De plus, nous avons supposé que la première introduction d’une variable d’environnement dans un projet au niveau du code se faisait dans le même commit que celui où nous avons placé notre variable d’environnement dans le docker-compose.
Afin de tester cette hypothèse, nous avons réalisé un programme Python qui parcourt parmi les fichiers docker-compose d’un projet, et en extrait, pour chaque variable d’environnement, les développeurs qui ont mis cette variable d’environnement une première fois dans le code, et les développeurs qui ont supprimé une variable d’environnement. Nous sommes donc parti à la recherche de projets open-source, déployés avec Docker et gérer via docker-compose. Cela fut relativement dur (peu de projets répondent à ce critère), mais nous avons trouvé un projet intéressant nommé Rocket.Chat disponible ici qui est un outil de messagerie et de collaboration open-source pour les équipes. Il contient à ce jour 22k commits, et le fichier docker-compose ressemble à ceci :
services:
rocketchat:
image: rocketchat/rocket.chat:latest
restart: unless-stopped
volumes:
- ./uploads:/app/uploads
environment:
- PORT=3000
- ROOT_URL=http://localhost:3000
- MONGO_URL=mongodb://mongo:27017/rocketchat
- MONGO_OPLOG_URL=mongodb://mongo:27017/local
- MAIL_URL=smtp://smtp.email
# - HTTP_PROXY=http://proxy.domain.com
# - HTTPS_PROXY=http://proxy.domain.com
depends_on:
- mongo
ports:
- 3000:3000
labels:
- "traefik.backend=rocketchat"
- "traefik.frontend.rule=Host: your.domain.tld"
Au niveau des variables d’environnement, la norme est que les variables d’environnements soient nommées par des mots en majuscules, séparées par des Under scores. Nous retrouvons cette syntaxe dans ce fichier docker-compose.
Nous allons donc, via une fonction regex qui doit reconnaitre ces variables d’environnements, remontrer les commits, afin de voir au fil du temps qui a ajouté/ supprimé une de ces variables d’environnement. La fonction REGEX que nous utilisons pour analyser le fichier docker-compose est celle-ci : ^\s*-\s(\w+)=(.*)$
En analysant le projet Rocket.Chat sous la branche alpine-base (15k commits), nous arrivons à trouver une paternité très large. Nous avons analysé ce projet grâce à l’algorithme hypothese_1.py, et nous avons regardé qui a le plus modifié des variables d’environnement dans le fichier docker-compose.yml (nous avons regardé les ajouts et les suppressions).
Globalement, notre résultat montre que le développeur Gabriel Engel a fait le plus de modifications de variables d’environnement dans le fichier docker-compose, il a donc une forte paternité au niveau du code (à la source).
{
"Gabriel Engel": {
"addition": 406,
"deletion": 213
},
"Guilherme Gazzo": {
"addition": 272,
"deletion": 184
},
"pkgodara": {
"addition": 34,
"deletion": 23
},
"Pradeep Kumar": {
"addition": 68,
"deletion": 46
},
"D\u00e1vid Balatoni": {
"addition": 34,
"deletion": 23
},
"Rodrigo Nascimento": {
"addition": 268,
"deletion": 150
},
"Peter Lee": {
"addition": 34,
"deletion": 23
}, ...
}
Cette première implémentation, relativement grossière, nous a permis de réorienter notre étude, mais globalement, donne déjà une vision très large de la paternité de l’ajout / retrait de variable d’environnement dans un projet déployé avec Docker.
Nous avons fait le choix d’invalider cette hypothèse à ce stade du projet, car nous nous sommes rendu compte de plusieurs choses :
La première étant que le nombre de fichiers open-source dockerisé est en réalité très faible. Par exemple, nous avons sur une dizaine de gros projets dockerisé (Portainer, Traefik, Jenkins, Nextcloud, …), nous n’avons trouvé qu’un seul projet qui est vraiment dockerisé via docker-compose.
De plus, nous nous sommes basés sur l’idée qu’une variable d’environnement est injecté via le fichier docker-compose, mais nous nous sommes aperçus grâce à plusieurs projets qu’en réalité, les fichiers docker-compose ne contiennent qu’une petite partie des variables d’environnements, surtout sur des projets Java Spring, ou celles-ci sont pour la majorité écrite dans les fichiers “.properties”. Par exemple, sur les projets précédemment cités, très rare sont ceux qui incluent les variables d’environnements dans leur docker-compose.
De plus, dans nos hypothèses, nous partions sur la supposition que le moment où un développeur ajoute une variable d’environnement à un fichier docker-compose, il utilise cette variable d’environnement quelque part dans le code. Sauf que cette idée ne peut pas être poursuivie pour 2 raisons.
La première étant qu’en général, notamment sur les gros projets, nous ne l’ajoutons pas au code au moment du même commit.
La seconde raison est que nous supposons que la variable d’environnement est injectée dans le code sous la même syntaxe, c’est-à-dire sous la forme majuscule et Under score. Cependant, nous avons vu que ce n’étais pas toujours le cas, notamment dans les projets Java Spring où la variable d’environnement peut être appelée dans le code sous la forme ma.variable.environement plutôt que MA_VARIABLE_ENVIRONNEMENT.
Maintenant que nous nous sommes rendu compte que se limiter aux projets qui utilisent un docker-compose nous contraignait, nous devons partir dans une autre direction.
Avec un peu de recul, dans l’hypothèse 1, notre ligne de conduite était de se dire “nous regardons qui a créé les variables d’environnements, et ensuite, nous iront les traiter dans le code”. Sauf que nous nous sommes aperçus que, trouver l’endroit où sont insérées toutes les variables d’environnement avant d’être injectées dans le code, est une tâche dure dans la mesure où chaque projet à sa manière de faire. Certains les mettent tous dans des fichiers docker-compose, d’autres dans des .env, d’autres les mettent nul part. La ligne de conduite de cette nouvelle hypothèse est de dire “nous allons regarder partout dans le code où nous trouvons des variables d’environnements (que ce soit un endroit où sont centralisées les variables d’environnements ou même dans le code), et ensuite de faire de l’analyse de paternité dessus”.
Notre premier problème est, globalement toujours le même, détecter des variables d’environnements. Voici un exemple des différents mécanismes d’utilisation des variables :
En python
import os
user = os.environ['USER']
En javascript
user = process.env.USER;
En java
@Value("${database.uri}")
private String database;
Il est également à noter que, pour chaque langage, notamment Java, il y a plusieurs manières d’injecter des variables d’environnements dans le code. Et souvent, ces mécanismes changent selon le Framework / librairie qui est utilisé. Nous allons donc, dans ce projet, nous limiter aux projets Java, car énormément de projets Open Source sont fait en java, et grâce à l’incubateur Apache, nous pouvons trouver des projets de taille différentes, allant de quelques centaines de commits (incubator-celeborn par exemple) à plusieurs milliers de commits (dubbo par exemple).
Nous allons aussi nous concentrer sur les projets Java utilisant le Framework SpringBoot. La raison principale est que les projets sous SpringBoot sont généralement des architectures backend, et c’est dans ce genre d’architecture que les variables d’environnements sont utilisée en majorité. C’est un choix arbitraire, ayant pour réelle ambition de nous faciliter le travail, car le but est de trouver des projets qui implémentent de la variabilité en fonction des variables d’environnements, nous avons donc trouvé cette direction (les projets Spring) plutôt bonne et plutôt en accord avec notre sujet.
La question qui se pose à nous maintenant est, comment trouver les variables d’environnements dans un projet Java Spring Boot ?
Une analyse de l’existant serait bien utile, et nous permettrait de potentiellement gagner du temps. Cependant, malgré plusieurs recherches de papiers scientifiques, nous n’avons rien trouvé de vraiment intéressant. Il y a beaucoup d’articles sur de l’analyse statique de code, mais pas vraiment d’article utile pour faire de la détection de variables d’environnements.
Cependant, nous avons fini par trouver un article qui aurait pu être intéressant, nommé “Automated Microservice Code-Smell Detection” [Walker et al]. Pour résumer, ils ont développé un outil open-source permettant de faire de l’analyse statique de code, mais sur des architectures micro-services. Cet outil permet de détecter les faiblesses de l’architecture.
Malgré le fait qu’ils évoquent une utilisation des variables d’environnement dans leur outil, nous n’avons pas pu trouver vraiment d’utilisation concrète de cet outil dans notre situation. De plus, après lecture rapide de leur code, nous n’avons rien trouvé de vraiment exploitable. Néanmoins, l’outil est réellement intéressant pour analyser des projets sous Spring Boot.
Nous devons donc nous orienter vers un outil développé par nos soins qui irai trouver les variables d’environnements dans un projet Java Spring Boot.
Une des grosses problématiques de notre projet est qu’en Spring Boot, les variables d’environnements ne sont pas injectées sous la forme classique (exemple : “MA_VARIABLE_ENVIRONNEMENT”), mais sous une forme spécifique (“ma.variable.environnement”), ce qui nous complique la tâche, car, Java est un langage orienté objet, et donc, faire de l’analyse statique pourrait générer énormément de faux positifs. En effet, l’exemple “ma.variable.environnement” peut-être une variable d’environnement, mais nous pourrions également avoir “environnement” qui est un attribut de la classe “variable” qui est un attribut de la classe “ma”.
Ce problème étant relevé, nous avons pensé à 2 solutions. La première étant de les détecter via analyse statique de code (comme l’hypothèse 1 par exemple), la seconde étant via analyse dynamique, c’est-à-dire exécuté le code, aller travailler dans la JVM pour trouver les variables d’environnements injectées, et ensuite faire des corrélations dans le code.
La seconde option fut très rapidement exclue, dû à la difficulté apparente que serait d’aller ouvrir la JVM. Potentiellement cela pourrait être une solution, avec plus de temps nous aurions pu explorer cette piste, mais il est vrai qu’à première vue, elle nous parait bien trop complexe à explorer.
L’analyse statique, quant à elle, s’annonce un peu plus compliquer que pour notre première hypothèse. Avec Java Spring Boot, il y a 3 pratiques courantes pour intégrer des variables d’environnements.
System.getenv()Par exemple, si nous voulons accéder à la variable d’environnement “MA_VARIABLE_ENVIRONNEMENT”, on peut créer une variable avec la ligne :
public int myVar = System.getenv("MA_VARIABLE_ENVIRONNEMENT");
.properties et à l’annotation @Value()Dans le fichier /ressources/application.properties
ma.variable.environnement=${MA_VARIABLE_ENVIRONNEMENT}
Dans le code
@Value("${ma.variable.environnement}")
private String myVar;
.properties, à l’annotation @Autowired et à la classe Environmentimport org.springframework.core.env.Environment;
@Autowired
private Environment env;
env.getProperty("ma.variable.environnement")
Globalement nous pouvons faire une première conclusion. Nous pouvons trouver dans les fichiers .properties les différentes variables d’environnements qui seront ensuite injecté dans le code. De plus, dans le code, nous avons 3 manières de trouver des variables d’environnements :
System.getenv( ... )@Value( ... )@Autowired suivi de “Environment”, avec l’import “import org.springframework.core.env.Environment;”Nous avons donc créé un programme sous python qui réalise 2 actions. Il va d’abord chercher les variables d’environnements dans les fichiers .properties, et ensuite, va regarder dans tout le projet s’il trouve un de ces 3 “mot-clé”.
Nous avons testé cet algorithme sur le projet spring-boot-admin disponible ici.
C’est un projet de moyenne envergure, mais il nous permet tout de même de trouver quelques variables d’environnements. Voici le résultat :
Environment variables in the .properties files
[
{
"file": "./spring-boot-admin/spring-boot-admin-server/src/test/resources/server-config-test.properties",
"env_variables": [
{
"injected_name": "spring.boot.admin.contextPath",
"value": "/admin"
},
{
"injected_name": "spring.boot.admin.instance-auth.default-user-name",
"value": "admin"
},
{
"injected_name": "spring.boot.admin.instance-auth.default-password",
"value": "topsecret"
},
{
"injected_name": "spring.boot.admin.instance-auth.service-map.my-service.userName",
"value": "me"
},
{
"injected_name": "spring.boot.admin.instance-auth.service-map.my-service.userPassword",
"value": "secret"
}
]
}
]
Found environment variables in code
[
{
"file": "./spring-boot-admin/spring-boot-admin-client/src/test/java/de/codecentric/boot/admin/client/AbstractClientApplicationTest.java",
"word": "@Autowired",
"line": "\t\t@Autowired\n"
},
{
"file": "./spring-boot-admin/spring-boot-admin-client/src/main/java/de/codecentric/boot/admin/client/config/InstanceProperties.java",
"word": "@Value(",
"line": "\t@Value(\"${spring.application.name:spring-boot-application}\")\n"
},
{
"file": "./spring-boot-admin/.mvn/wrapper/MavenWrapperDownloader.java",
"word": "System.getenv",
"line": " if (System.getenv(\"MVNW_USERNAME\") != null && System.getenv(\"MVNW_PASSWORD\") != null) {\n"
},
{
"file": "./spring-boot-admin/.mvn/wrapper/MavenWrapperDownloader.java",
"word": "System.getenv",
"line": " String username = System.getenv(\"MVNW_USERNAME\");\n"
},
{
"file": "./spring-boot-admin/.mvn/wrapper/MavenWrapperDownloader.java",
"word": "System.getenv",
"line": " char[] password = System.getenv(\"MVNW_PASSWORD\").toCharArray();\n"
},
{
"file": "./spring-boot-admin/spring-boot-admin-server/src/test/java/de/codecentric/boot/admin/server/config/AdminServerPropertiesTest.java",
"word": "@Autowired",
"line": "\t@Autowired\n"
},
{
"file": "./spring-boot-admin/spring-boot-admin-server/src/main/java/de/codecentric/boot/admin/server/config/AdminServerHazelcastAutoConfiguration.java",
"word": "@Value(",
"line": "\t@Value(\"${spring.boot.admin.hazelcast.event-store:\" + DEFAULT_NAME_EVENT_STORE_MAP + \"}\")\n"
},
{
"file": "./spring-boot-admin/spring-boot-admin-server/src/main/java/de/codecentric/boot/admin/server/config/AdminServerHazelcastAutoConfiguration.java",
"word": "@Value(",
"line": "\t\t@Value(\"${spring.boot.admin.hazelcast.sent-notifications:\" + DEFAULT_NAME_SENT_NOTIFICATIONS_MAP + \"}\")\n"
},
{
"file": "./spring-boot-admin/spring-boot-admin-server-ui/src/test/java/de/codecentric/boot/admin/server/ui/config/AdminServerUiPropertiesTest.java",
"word": "@Autowired",
"line": "\t@Autowired\n"
}
]
Nous pouvons voir que nous ne trouvons qu’un seul fichier .properties, contenant 5 variables d’environnements, et, nous avons trouvé dans le code 9 endroits où l’on fait appel à une variable d’environnement. Respectivement 3 avec le mot clé @Autowired, 3 avec le mot clé @Value, et 3 avec le mot clé System.getenv. Dans un projet, il n’y a donc pas qu’une seule manière d’utiliser des variables d’environnements, ce qui n’est pas forcément à notre avantage. De plus, pour un projet qui a plus de 2000 commits, nous remarquons qu’il n’y a pas tant d’utilisation de variable d’environnements, ce qui peut, potentiellement être une faille de sécurité (peut-être qu’il existe des variables qui devraient être des variables d’environnement, mais dont la valeur est écrite directement dans le code). Une autre chose à noter est que,la variable d’environnement spring.application.name:spring-boot-application ne se trouve dans aucun fichier .properties. Cependant, elle est utilisée quelque part. Cette variable d’environnement est sûrement située dans un fichier .properties de Spring Boot directement, et elle est appelée ensuite par spring-boot-admin. On se rend compte donc qu’il ne faut pas se fier à 100% au fichier .properties, mais qu’il faut aussi aller chercher des variables d’environnements “à la main” dans le code directement. Nous ne pouvons pas prendre les variables d’environnement situé dans le fichier .properties et ensuite aller chercher ces variables d’environnements dans le code, nous passerions à côté de beaucoup d’entre elles. D’ailleurs, aucune des variables d’environnements trouver dans le fichier .properties n’a été retrouvée quelque part dans le code, ce qui peut également représenter un “code-smell”.
Une limite aussi de notre algorithme est qu’il ne va pas chercher les lignes où les variables d’environnements sont utilisées quand il détecte le mot clé @Autowired(). C’est une hypothèse que l’on prend, on supposera que l’on mesurera la variabilité par rapport à ce mot clé. Cette hypothèse est choisie par manque de temps de pousser le projet plus loin, et par manque d’organisation au sein du groupe.
Nous avons, dans cette première partie, mis un accent sur la recherche de variables d’environnements. Nous avons d’abord essayé une approche qui se voulait générique par fichier docker-compose, mais nous nous sommes finalement rendu compte que cette approche était bien plus restrictive que générique.
Nous avons donc dû aller chercher les variables d’environnement directement dans les projets. Pour que ce soit plus simple, nous avons décidé de nous concentrer sur les projets sous Java Spring Boot, car ce sont des web services qui utilisent régulièrement des variables d’environnements. De là, nous avons pu extraire certaines variables d’environnements, toujours en supposant certaines hypothèses telles que la recherche par mot clé.
La conclusion de cette première partie est que, il est très compliqué de trouver des variables d’environnements dans un projet, surtout si ce projet utilise plusieurs langages. De plus, selon le langage de programmation que nous utilisons, il y a des manières différentes d’utiliser des variables d’environnements, et au-dessus de cela, le Framework utilisé rajoute des éventuelles possibilités.
Cette partie pourrait mener à une étude et à un outil bien plus approfondi, car réellement compliqué. Cet outil pourrait avoir comme fin de l’analyse statique afin de faire de la détection de bug, mais aussi, et c’est notre prochaine partie, l’analyse de paternité.
Malgré le fait que nos hypothèses de la partie précédente impliquent que seulement une partie des variables d’environnement peuvent être détectées, il n’empêche en rien le fait de pouvoir mesurer la paternité sur ces même variables d’environnements, et de calculer un pourcentage.
Nous allons donc reprendre le programme situé dans hypothese_2 et nous allons l’adapter afin qu’il puisse lire des commits, et rechercher dans chaque commit s’il y a eu une modification d’une variable d’environnement au fil du temps.
Comme premier exemple, nous avons utilisé le projet spring-boot-admin et nous sommes allés récupérer les contributions. Vous retrouverez le programme dans le fichier /part2, avec les résultats sous forme de JSON dans les répertoires des projets respectifs.
Nous obtenons ce résultat :
{
"Fedor Bobin": {
"addition": 2,
"deletion": 0,
"contributions": 2,
"total_contribution_percentage": 2.898550724637681,
"addition_percentage": 2.898550724637681,
"deletion_percentage": 0.0
},
"Stephan K\u00f6ninger": {
"addition": 6,
"deletion": 0,
"contributions": 6,
"total_contribution_percentage": 8.695652173913043,
"addition_percentage": 8.695652173913043,
"deletion_percentage": 0.0
},
"Johannes Edmeier": {
"addition": 32,
"deletion": 0,
"contributions": 32,
"total_contribution_percentage": 46.3768115942029,
"addition_percentage": 46.3768115942029,
"deletion_percentage": 0.0
},
"Daniel Reuter": {
"addition": 7,
"deletion": 0,
"contributions": 7,
"total_contribution_percentage": 10.144927536231885,
"addition_percentage": 10.144927536231885,
"deletion_percentage": 0.0
}
}
Nous avons volontairement retiré certains contributeurs afin que ce ne soit pas trop long, mais vous pouvez retrouver ce JSON dans le dossier part2. Nous pouvons voir que Johannes Edmeier a ajouté 32 variables d’environnements et a un pourcentage de contribution de 46%. Le score de contributions est calculé comme ceci :
total_contribution_percentage = (additionsUser + deletionsUser) / (additionsTotal + deletionsTotal)
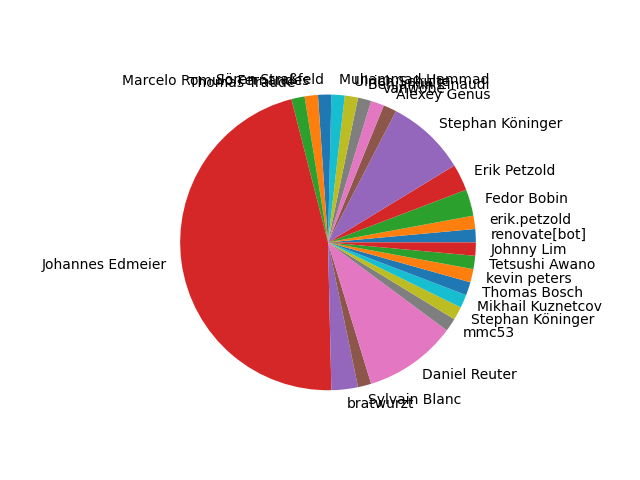
Il donne ainsi le pourcentage de paternité associé à cet utilisateur. Ce programme nous permet donc rapidement de visualiser qui est le responsable majoritaire des modifications. De plus, grâce à un pie-chart, nous pouvons visualiser encore plus simplement et directement voir s’il y a un déséquilibre dans le projet ou non, ce qui permet au chef de projet de prendre des dispositions.
Afin de tester à plus grande échelle notre algorithme, nous l’avons lancé sur plusieurs autres projets, pour cela, nous avons fait une liste de projets intéressant à tester et nous avons fait des récapitulatifs :
| Projet | Spring Cloud Netflix | Spring Boot Admin | Dubbo | Spring Initializr | Kafdrop |
|---|---|---|---|---|---|
| Nombre de commits | 3032 | 2018 | 288 | 2094 | 619 |
| Nombre de contributeurs | 209 | 123 | 50 | 85 | 56 |
| Nombre de contributeurs var env | 50 | 24 | 5 | 10 | 10 |
| Pourcentage de contributeurs totaux qui ont intérféré avec les var en | 23,92% | 19,51% | 10,00% | 11,76% | 17,86% |
| Pourcentage du plus gros contributeurs | 26,60% | 46,38% | 57,90% | 71,73% | 25% |
| Pourcentage d’issues qui sont des bugs | 7,40% | 20,62% | 4,66% | 9,75% | 3,64% |
Nous pouvons voir que sur certains projets, notamment sur Spring Initializr, les modifications des variables d’environnement sont très largement concentrées chez un seul développeur, à plus de 71%. Pareil pour Spring Boot Admin et Dubbo. Nous ne trouvons pas vraiment de corrélations avec le nombre de commit, nous voyons même qu’avec plus de 2000 commits, nous trouvons quand même de très gros pourcentage, ce qui permet de dire que le développeur qui a 71% et 57% a vraiment un fort impact sur les modifications des variables d’environnement du projet, et qu’il ne faudrait pas forcément que ce développeur quitte le projet.
Globalement, nous remarquons que le pourcentage de développeur qui interfère avec les variables d’environnement est globalement entre 10% et 20%, soit environ 1 personne sur 5 ou sur 10. C’est rassurant car cela signifie qu’une partie non négligeable des développeurs touche tout de même à ces variables.
Nous avons essayé de voir si nous trouvions une corrélation avec le nombre de bug dans le code. Nous nous sommes donc inspirés de plusieurs papiers scientifiques pour calculer un pourcentage de “bug” dans le code (à très gros grain). Nous avons juste divisé le nombre d’issues GitHub qui ont un tag bug avec le nombre total d’issues. Les résultats ne sont pas convaincants, nous ne pouvons pas, grâce à nos données actuelles, nous positionner sur une corrélation entre le pourcentage de modification duplus gros contributeur et le pourcentage de bugs.
Dans cette partie nous avons appliqué la recherche de mot clés liées à des variables d’environnements dans les projets Java Spring Boot avec une analyse des commits au fil du temps.
Nos recherches ont clairement démontré que dans certains projets, la gestion des variables d’environnement est souvent gérée en majorité par un seul développeur, rendant donc le projet très dépendant de ce même développeur. Ces résultats sont cependant à prendre très avec des pinces car, dans un premier temps, nous avons fait énormément d’hypothèses. Notamment sur la recherche de variables d’environnements dans le code, il se peut en effet que nous n’ayons pas toutes les formes d’implémentations de variables d’environnement, et que nous passons donc à côté de nombreuses d’entre elles.
De plus, nous réalisons des mesures qui ne sont pas forcément dans le contexte du projet. Il serait intéressant d’utiliser d’autres métriques sur ces mêmes projets, afin de pouvoir les comparer entre elles, et d’avoir un recul supplémentaire.
De plus, nos données, même si nous avons essayé de les vérifier en faisant des recherches “à la main” directement dans les fichiers GitHub, ne sont potentiellement pas dépourvues d’erreurs.
Dans cette recherche, nous avons fait face à une contrainte de taille, que nous n’avons trouver qu’une partie de la solution en acceptant des hypothèses fortes, qui est la recherche de variables d’environnements dans un projet. Très peu de documentation parle de ce problème, et très peu d’outils existent. De notre point de vue, cet aspect de notre projet est un sujet de recherche à part entière. Une fois ces variables d’environnements détectées dans un projet Java Spring Boot, nous avons mesuré la paternité de l’édition de ces variables d’environnements, et nous en avons conclu que dans beaucoup de projets, même de gros projets avec plusieurs milliers de commit, il arrive souvent que ces modifications soit en majorité faites par seulement un développeur. Cela peut impliquer des problèmes si ce développeur venait à quitter le projet.
Nous n’avons pas réussi à relever le challenge 3 qui était de générer l’arbre généalogique des variables d’environnements, par manque de temps. De plus, nous aurions aimé aller plus loin dans l’analyse de donnée et la génération de statistiques, nous aurions aimé trouver des corrélations entre la paternité et des potentielles autres métriques.
Pour l’avenir, il faudrait perfectionner l’outil de recherche de variable d’environnement, il faudrait même en créer un outil, open-source ou non, qui permet de trouver les variables d’environnements dans un projet, multi-langages ou non. En effet, cette analyse statique de recherche de variables d’environnement dans un code est très utile pour des architectures micro-services, ou même des API ou backends. Suite à cela, il faudrait prendre plus de temps pour analyser les résultats, les comparer et lancer des analyses sur des projets de plus grande ampleur, afin de confirmer ou infirmer nos résultats.
Malgré le fait que nous soyons un peu attristés de ne pas avoir pu pousser l’analyse plus loin, nous sommes globalement contents d’avoir réussi à créer une base, que l’on espère solide, pour une poursuite de ce sujet d’étude, qui, nous l’espérons, découlera sur un outil qui aurait un réel intérêt dans l’industrie et dans de la gestion de projet.
![]()